My research relies on different kinds of data and methods. I let the question guide the selection of data and method rather than the other way around.
Two kinds of data are (often) better than one.
Social scientists now turn to mixed-methods studies that involve multiple kinds of data and/or multiple strategies of analysis. This allows researchers to overcome potential shortcomings of any one method and approach the same problem from multiple angles. I have combined qualitative information from interviews with quantitative data from surveys in my book, a sole-authored paper on internal migration in Thailand as well as joint work on Mexican migration with Asad Asad. I have also blended simulations with empirical analysis.
Computers need humans (and vice versa).
Machine learning tools—which use algorithms to extract information from data—are becoming increasingly popular in the social sciences. With Mario Molina, we provided a review of recent applications. I have used unsupervised machine learning methods in a sole-authored paper and book as well as in collaborative articles with Asad Asad and Lucas Drouhot. These methods are good for discovering hidden patterns, but also require key input from the researcher.
Sometimes it is best to make up your own data.
It is hard to test for complex theoretical mechanisms with observational data. Researchers often turn to agent-based models which simulate agents in interaction, and typically produce emergent macro-levels patterns. We have used this tool to link homophily and consolidation to diffusion and inequality.
Diffusion Figure
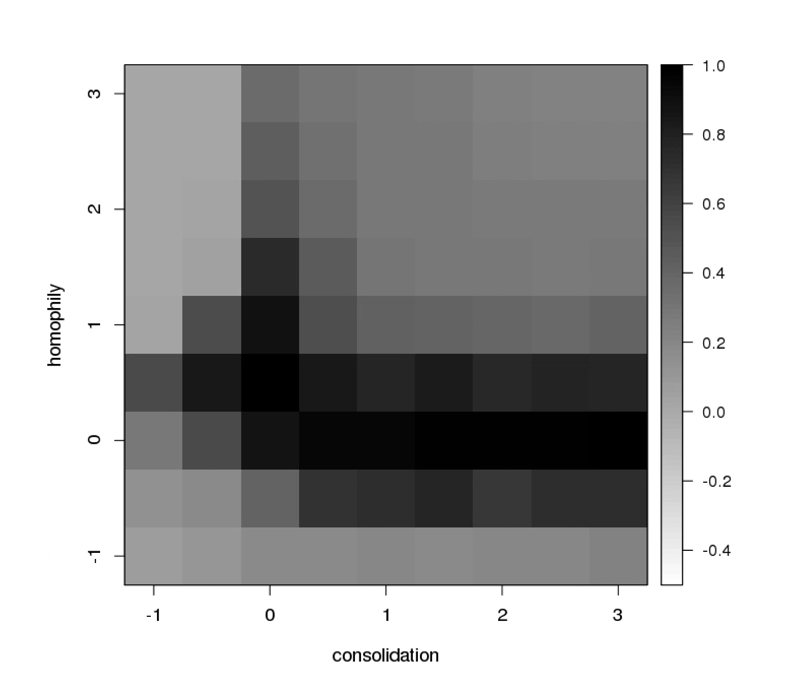
Diffusion of a practice under different degrees of homophily and consolidation. (Figure from Zhao & Garip 2019 SMR)